

nevertheless
[논문 리뷰] MobileNetV2 내용 정리 본문
짧게 요약하자면
- MobileNetV2는 모바일 환경을 위한 경량 CNN으로,
- inverted residual과 linear bottleneck을 통해
- 연산량과 메모리를 줄이면서도 정확도를 유지/개선한 모델이다.
왜 MobileNetV2가 필요한가
- 기존 CNN(ResNet, VGG 등)은 성능은 좋지만 무거움
- 모바일/임베디드 환경에서는 연산량, 메모리, latency가 중요함
- MobileNetV1이 이미 가벼운 구조를 제안했지만, 정확도와 표현력 면에서 한계가 있었다
- 그래서 MobileNetV2는 가벼움을 유지하면서(연산량과 메모리 양을 줄이며) 정확도를 더 높이는 것이 목표!
MobileNetV2의 핵심 아이디어
1. Depthwise Separable Convolution
: 일반 convolution을 두 단계로 분리하는 방법
[ 일반 convolution ]
- 입력 크기: $ h_i \times w_i \times d_i $
- 출력 채널 수: $ d_j $
- 커널 크기: $ k \times k $
- 연산량: $ h_i \cdot w_i \cdot d_i \cdot d_j \cdot k^2 $
[ depthwise separable convolution ]
위 일반 convolution의 연산을 두 단계로 나눔
1) depthwise convolution
- 각 입력 채널마다 독립적으로 convolution 수행
- 채널 간 결합 없음
- 연산량: $ h_i \cdot w_i \cdot d_i \cdot k^2 $
2) pointwise convolution
- 채널을 선형 결합
- 새로운 feature 생성
- 연산량: $ h_i \cdot w_i \cdot d_i \cdot d_j $
-> 총 연산량: $ h_i \cdot w_i \cdot d_i ( k^2 + d_j ) $
이는 일반 convolution보다 약 8~9배 정도 연산량이 감소하게 된다.
즉, MobileNetV2는 공간 연산과 채널 결합을 분리하여 계산량을 크게 줄인다.
2. Linear Bottleneck
CNN에서는 보통 convolution 뒤에 ReLU같은 비선형 활성화 함수를 사용한다.
그러나 이 논문에서의 관찰으로는, CNN의 activation tensor는 고차원 공간이지만 실제 데이터는 저차원 manifold에 존재한다.
-> 즉, activation 공간은 고차원이지만, 실제 의미 있는 데이터(manifold of interest, 우리가 관심을 가지는 데이터)는 저차원 부분공간에 존재한다.
이 상황에서 ReLU 같은 non-linear 함수는 정보를 손실시킬 가능성이 있다.
특히 채널 수가 적은 bottleneck 공간에서 ReLU를 사용하면 정보 손실이 크게 발생할 수 있다.
따라서 MobileNetV2에서는
- 확장된 공간에서는 ReLU 사용
- bottleneck에서는 ReLU 제거 (linear)
즉, 다음과 같은 Linear Bottleneck 구조를 따른다.
Expand → ReLU → Depthwise → ReLU → Linear Projection
3. Inverted Residual
ResNet의 residual block 구조는 다음과 같다.

-> 즉, 채널 수가 많은 공간에서 shortcut 연결이 이루어진다.
반면 MobileNetV2는 다음과 같은 구조를 사용한다.

-> 이를 Inverted Residual 구조라고 한다.
즉 비교하자면 다음과 같다.
- Residual block: Wide → Narrow → Wide
- Inverted residual block: Narrow → Wide → Narrow
핵심 아이디어는 다음과 같다.
- 실제 중요한 정보는 bottleneck(좁은 채널 공간)에 존재한다.
- 확장된 채널 공간은 비선형 변환을 위한 작업 공간으로 사용된다.
- shortcut은 확장층끼리 연결하지 않고, 좁은 bottleneck 사이에서 연결
연산량을 비교하자면 다음과 같다.
- Residual block: $ h_i \cdot w_i \cdot d_i ( k^2 + d_j ) $
- Inverted residual block: $ h_i \cdot w_i \cdot d_i ( d' + k^2 + d''' ) $
-> 입력과 출력의 채널 수가 더 적기 때문에, inverted residual block의 연산량이 더 적음
즉, 이 구조는 메모리 효율성과 연산 효율성을 동시에 개선한다.
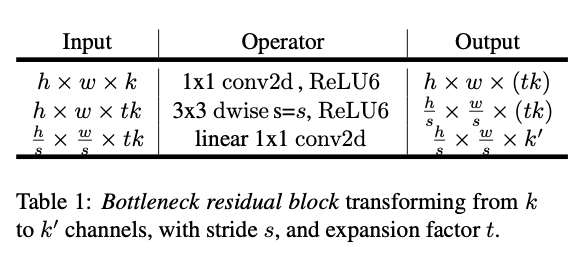
Bottleneck Block 구조 상세 설명
MobileNetV2의 기본 블록은 Bottleneck Residual Block이다.
논문에서는 이 블록을 다음과 같이 표현한다.
$ F(x) = [A \circ N \circ B]x $
- B: 확장 (expand)
- N: depthwise + ReLU6
- A: projection (linear)
구조는 다음과 같다.
x (k channels)
│
1×1 conv (expand)
│
t·k channels
│
3×3 depthwise conv
│
t·k channels
│
1×1 conv (projection)
│
y (k channels)
여기서 expansion ratio t는 보통 6으로 설정된다.
또한 non-linearlity는 ReLU6을 사용한다. (음수면 0, 0~6은 그대로, 6보다 크면 6으로 클리핑)
-> 이 activation은 모바일 환경에서의 정수 연산에 유리하다.

MobileNet V2에서는 stride 값에 따라 두 가지 블록으로 나뉘게 된다.
- stride 1
inverted residual block에서 skip connection을 진행
- stride 2
블록 구조는 stride 1과 동일하나 skip connection을 생략하고 Depthwise convolution에서 stride 2를 통한 downsampling을 진행
전체 네트워크 구조

MobileNetV2 전체 구조는 다음과 같다.
- 초기 3x3 convolution (32 filters)
- 19개의 bottleneck residual block
- 마지막 1x1 convolution
- global avarage pooling
- classifier
모든 bottleneck block은 다음 특징을 가진다.
- depthwise separable convolution 사용
- inverted residual 구조
- linear bottleneck 적용
- ReLU6 activation 사용
- kernel size = 3×3
또한 MobileNetV2는 다음 두 하이퍼 파라미터를 통해 성능과 연산량을 조절할 수 있다.
1. Input Resolution: 입력 이미지 크기 조절(이미지 크기 ↓ → 정보량 ↓)
2. Width Multiplier: 채널 수를 일정 비율로 줄임(채널 ↓ → 표현력 ↓)
* 단, V1과 다르게, width multiplier < 1일 때, 마지막 conv에서는 multiplier 적용 안 함 (작은 모델에서의 성능 향상을 위해)
역할 차이를 보자면,
resolution 줄이면 -> 공간 정보 감소 -> 이미지가 흐릿해짐
width 줄이면 -> feature 다양성 감소 -> 모델이 덜 똑똑해짐
이 두 파라미터를 조절해 accuracy와 연산량 사이의 trade-off를 조정할 수 있다.
연산량 및 메모리 효율 분석
(1) 연산량 분석
MobileNetV2 bottleneck block의 연산량은 다음과 같이 계산된다.
$ h \cdot w \cdot d' \cdot t (d' + k^2 + d'') $
- d': 입력 채널
- d'': 출력 채널
- t: expansion ratio
- k: kernel size
연산량은 세 개의 convolution을 더해서 계산된다.
1. Expansion Conv
$ h w d' (t d') = h w t d'^2 $
2. Depthwise Conv
$ h w (t d') k^2 $
3. Projection Conv
$ h w (t d') d'' $
전체 연산량: $ h w d' t (d' + k^2 + d'') $
겉보기에는 convolution이 많아 보이지만,
채널 수가 작고, depthwise convolution이 사용되기 때문에
전체 연산량은 일반 residual block보다 작다.
(2) 메모리 효율 분석
일반적인 딥러닝 프레임워크는 연산을 DAG (Directed Acyclic Graph) 형태로 표현한다.
이때 메모리 사용량은 중간 tensor 크기에 크게 영향을 받는다.
MobileNetV2의 구조는 Narrow -> Wide -> Narrow 이므로
구조에서 Wide 텐서를 장시간 메모리에 저장할 필요 없다.
즉, 확장된 tensor는 임시 계산용이며, 계산 후 바로 버릴 수 있다.
따라서 전체 메모리 사용량은 확장층(Wide)이 아니라 bottleneck 크기(Narrow)에 의해 결정된다.
이 덕분에 작은 cache 메모리에서도 효율적으로 실행할 수 있다.
논문의 의의와 한계
MobileNetV2의 가장 중요한 기여는 다음과 같다.
- inverted residual 구조 제안
- linear bottleneck 구조 도입
- 연산량과 메모리 사용 감소
- 모바일 환경에 적합한 CNN 구조 제시
특히 이 논문은
- capacity (정보 저장 공간)과
- expressiveness (비선형 표현력)을 분리했다.
이 설계는 이후 많은 경량 CNN 설계에 영향을 미쳤다.
하지만 이 논문의 한계는 다음과 같다.
- 여전히 accuracy와 model size 사이 trade-off 존재
- 고성능 서버용 모델보다는 모바일 환경에 최적화
- 구조 이해가 비교적 복잡
결론
MobileNetV2는 inverted residual과 linear bottleneck을 기반으로 한 경량 CNN 구조를 제안하였다.
이 구조는 다음과 같은 장점을 가진다.
- 연산량 감소
- 메모리 효율 증가
- 모바일 환경에서 높은 성능 유지
실험 결과에서도 MobileNetV2는
- ImageNet classification
- Object detection
- Semantic segmentation
등 다양한 작업에서 높은 효율성과 경쟁력 있는 성능을 보여주었다.
따라서 MobileNetV2는 모바일 환경을 위한 대표적인 CNN 아키텍처로 평가된다.
'AI > 논문 리뷰' 카테고리의 다른 글
| Block 연산량 비교: VGGNet, ResNet, MobileNetV2 (0) | 2026.04.04 |
|---|---|
| [논문 리뷰] MobileNetV2 Implementation (0) | 2026.03.29 |
| [논문 리뷰] ResNet Implementation (0) | 2026.03.29 |
| [논문 리뷰] VGGNet 내용 정리 (0) | 2026.03.29 |
| [논문 리뷰] ResNet 내용 정리 (1) | 2026.03.01 |