

nevertheless
[논문 리뷰] ResNet Implementation 본문
ResNet 논문을 읽은 뒤 CIFAR-10 분류 실험을 위해 ResNet56을 직접 구현하고 학습해보았다.
논문 정리: https://orchidbyw1.tistory.com/5
모델 설정
- 코드 베이스: kuangliu/pytorch-cifar 참고
- 데이터셋: CIFAR-10
- 모델: ResNet56
- BasicBlock 기반
- block 수: [9, 9, 9]
- 초기 채널 수: 16
- 초기 convolution: 3×3, stride=1
ResNet56은 CIFAR용 ResNet 구조를 기준으로 하며, 3개의 stage에 각각 9개의 BasicBlock을 쌓는 방식이다.
초기 convolution도 ImageNet용 ResNet처럼 7×7이 아니라, CIFAR-10 입력 크기(32×32)에 맞게 3×3 conv를 사용했다.
학습 설정
- Epoch: 200
- Batch size: 128
- Optimizer: SGD
- Learning rate: 0.1
- Momentum: 0.9
- Weight decay: 5e-4
학습은 ResNet 논문과 CIFAR 구현들에서 자주 사용하는 설정을 최대한 따랐다.
특히 SGD + momentum, 그리고 weight decay를 사용해 안정적으로 학습되도록 했다.
데이터 전처리
- RandomCrop(32, padding=4)
- RandomHorizontalFlip
- Normalize: (0.4914, 0.4822, 0.4465) / (0.2023, 0.1994, 0.2010)
모델 구현
import torch
import torch.nn as nn
import torch.nn.functional as F
def forward(self, x):
return self.lambd(x)
def conv3x3(in_planes, planes, stride=1):
return nn.Conv2d(in_planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
def conv1x1(in_planes, planes, stride=1):
return nn.Conv2d(in_planes, planes, kernel_size=1, stride=stride, padding=0, bias=False)
class BasicBlock(nn.Module): # nn.Module 상속받음
expansion = 1 # 출력 채널 수 동일
def __init__(self, in_planes, planes, stride=1): # 출력 채널이 동일하므로 stride=1
super(BasicBlock, self).__init__() # nn.Module 초기화부터
self.conv1 = conv3x3(in_planes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = conv3x3(planes, planes)
self.bn2 = nn.BatchNorm2d(planes)
self.shortcut = nn.Sequential() # 기본은 identity
# 이후근데 연산에서 shortcut을 더해야 하는데(F(x)+x)
if stride != 1 or in_planes != planes: # 차원이 안 맞는 경우
# projection shortcut = 1x1 conv로 맞춤
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, self.expansion * planes, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion*planes)
)
def forward(self, x): # 블록 출력
out = self.conv1(x)
out = self.bn1(out)
out = F.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out += self.shortcut(x) # 필요에 따라 layer를 건너뜀
out = F.relu(out)
return out
class BottleNeck(nn.Module):
expansion = 4 # 채널 수 4배 증가
def __init__(self, in_planes, planes, stride=1): # 출력 채널이 동일하므로 stride=1
super(BottleNeck, self).__init__() # nn.Module 초기화부터
# 1x1 convolution -> 채널 줄임
self.conv1 = conv1x1(in_planes, planes, stride=1)
self.bn1 = nn.BatchNorm2d(planes)
# 3x3 convolution -> 줄인 채널로 연산 수행
self.conv2 = conv3x3(planes, planes, stride)
self.bn2 = nn.BatchNorm2d(planes)
# 1x1 convolution -> 채널 다시 늘림
self.conv3 = conv1x1(planes, self.expansion * planes, stride=1)
self.bn3 = nn.BatchNorm2d(self.expansion * planes)
self.shortcut = nn.Sequential() # 기본은 identity
# 이후 연산에서 shortcut을 더해야 하는데(F(x)+x)
if stride != 1 or in_planes != self.expansion * planes: # 차원이 안 맞는 경우
# projection shortcut = 1x1 conv로 맞춤
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, self.expansion * planes, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion*planes)
)
def forward(self, x): # 블록 출력
out = self.conv1(x)
out = self.bn1(out)
out = F.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = F.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out += self.shortcut(x)
out = F.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, num_blocks, num_classes=10): # CIFAR10은 분류할 클래스 수가 10개
super(ResNet, self).__init__() # nn.Module 초기화부터
self.in_planes = 16 # 입력 채널 수
# ResNet 논문 구조 적용.
self.conv1 = nn.Conv2d(3, 16, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(self.in_planes)
self.layer1 = self._make_layer(block, 16, num_blocks[0], stride=1)
self.layer2 = self._make_layer(block, 32, num_blocks[1], stride=2)
self.layer3 = self._make_layer(block, 64, num_blocks[2], stride=2)
# FC layer -> Basic Residual Block일 경우 그대로, BottleNeck일 경우 4를 곱함
self.linear = nn.Linear(64 * block.expansion, num_classes)
def _make_layer(self, block, planes, num_blocks, stride):
strides = [stride] + [1]*(num_blocks-1) # 첫 block만 stride로 downsampling하고, 나머지는 크기 유지
layers = []
for stride in strides: # stride별로 돌면서 block을 생성
layers.append(block(self.in_planes, planes, stride))
self.in_planes = planes * block.expansion # 다음 block의 채널 수 업데이트
return nn.Sequential(*layers) # 만든 block 리스트 보냄
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x))) # 초기 추출
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = F.avg_pool2d(out, out.size()[3]) # 공간 크기를 줄여서 (HxW -> 1x1)
out = out.view(out.size(0), -1) # flatten
out = self.linear(out) # fully connected
return out
학습 및 테스트
import copy
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import torch.backends.cudnn as cudnn
from torch.utils.data import DataLoader, random_split
import matplotlib.pyplot as plt
# =========================================================
# 0. 기본 세팅
# =========================================================
# GPU 사용 가능하면 GPU 사용
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print("Device:", device)
# epoch 수
num_epochs = 200
# batch size
train_batch_size = 128
eval_batch_size = 100
# 재현성을 위해 seed 고정
seed = 42
torch.manual_seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed_all(seed)
# =========================================================
# 1. 데이터 전처리
# =========================================================
# train용 transform
# 데이터 증강 포함
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4), # 32x32 이미지 주변 padding 후 랜덤 crop
transforms.RandomHorizontalFlip(), # 좌우 반전
transforms.ToTensor(), # Tensor 변환
transforms.Normalize((0.4914, 0.4822, 0.4465), # CIFAR-10 mean
(0.2023, 0.1994, 0.2010)) # CIFAR-10 std
])
# val / test용 transform
# 성능 평가용이므로 augmentation 없이 정규화만 수행
transform_eval = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465),
(0.2023, 0.1994, 0.2010))
])
# =========================================================
# 2. 데이터셋 준비
# =========================================================
# CIFAR-10 train 전체(50000장)를 먼저 불러옴
# 여기서 train / validation으로 다시 분리할 것
full_trainset = torchvision.datasets.CIFAR10(
root='./data',
train=True,
download=True,
transform=transform_train # 우선 train transform으로 불러옴
)
# validation용 데이터는 augmentation이 없어야 하므로
# 같은 train=True 데이터를 transform_eval로 하나 더 불러옴
full_valset = torchvision.datasets.CIFAR10(
root='./data',
train=True,
download=True,
transform=transform_eval
)
# train/val 분할 비율 설정
# 예: 45000 / 5000
train_size = 45000
val_size = 50000 - train_size
# 같은 인덱스로 나누기 위해 generator에 seed 고정
generator = torch.Generator().manual_seed(seed)
# 인덱스 기준으로 train / val 분할
train_subset_indices, val_subset_indices = random_split(
range(50000),
[train_size, val_size],
generator=generator
)
# random_split이 Subset 객체를 반환하므로 indices 추출
train_indices = train_subset_indices.indices
val_indices = val_subset_indices.indices
# trainset / valset 생성
trainset = torch.utils.data.Subset(full_trainset, train_indices)
valset = torch.utils.data.Subset(full_valset, val_indices)
# test set은 마지막 최종 평가용
testset = torchvision.datasets.CIFAR10(
root='./data',
train=False,
download=True,
transform=transform_eval
)
# =========================================================
# 3. DataLoader 준비
# =========================================================
trainloader = DataLoader(
trainset,
batch_size=train_batch_size,
shuffle=True, # train은 섞음
num_workers=2
)
valloader = DataLoader(
valset,
batch_size=eval_batch_size,
shuffle=False, # val은 섞을 필요 없음
num_workers=2
)
testloader = DataLoader(
testset,
batch_size=eval_batch_size,
shuffle=False, # test도 섞을 필요 없음
num_workers=2
)
# =========================================================
# 4. 모델 준비
# =========================================================
net = ResNet(BasicBlock, [9, 9, 9])
net = net.to(device)
if device == 'cuda':
net = torch.nn.DataParallel(net) # 여러 GPU 사용 가능 시 병렬 처리
cudnn.benchmark = True
# =========================================================
# 5. loss / optimizer / scheduler
# =========================================================
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(
net.parameters(),
lr=0.1,
momentum=0.9,
weight_decay=5e-4
)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(
optimizer,
T_max=num_epochs
)
# =========================================================
# 6. 학습 함수
# =========================================================
def train_one_epoch(model, loader, criterion, optimizer, device):
"""
한 epoch 동안 학습 수행
반환값:
- avg_loss: epoch 평균 train loss
- acc: epoch train accuracy
"""
model.train() # 학습 모드
running_loss = 0.0
correct = 0
total = 0
for inputs, targets in loader:
# 데이터를 device로 이동
inputs, targets = inputs.to(device), targets.to(device)
# gradient 초기화
optimizer.zero_grad()
# forward
outputs = model(inputs)
# loss 계산
loss = criterion(outputs, targets)
# backward
loss.backward()
# weight update
optimizer.step()
# loss 누적
running_loss += loss.item()
# accuracy 계산
_, predicted = outputs.max(1)
total += targets.size(0)
correct += predicted.eq(targets).sum().item()
avg_loss = running_loss / len(loader)
acc = 100.0 * correct / total
return avg_loss, acc
# =========================================================
# 7. 평가 함수 (validation / test 공용)
# =========================================================
def evaluate(model, loader, criterion, device):
"""
validation / test 공용 평가 함수
반환값:
- avg_loss: 평균 loss
- acc: accuracy
"""
model.eval() # 평가 모드
running_loss = 0.0
correct = 0
total = 0
with torch.no_grad(): # gradient 계산 비활성화
for inputs, targets in loader:
inputs, targets = inputs.to(device), targets.to(device)
outputs = model(inputs)
loss = criterion(outputs, targets)
running_loss += loss.item()
_, predicted = outputs.max(1)
total += targets.size(0)
correct += predicted.eq(targets).sum().item()
avg_loss = running_loss / len(loader)
acc = 100.0 * correct / total
return avg_loss, acc
# =========================================================
# 8. 기록용 리스트
# =========================================================
train_losses = []
train_accs = []
val_losses = []
val_accs = []
# validation 기준 최고 성능 기록
best_val_acc = 0.0
best_epoch = 0
# 가장 성능이 좋았던 모델 가중치 저장용
best_model_wts = copy.deepcopy(net.state_dict())
# =========================================================
# 9. 메인 학습 루프
# =========================================================
print("----- Start Training -----")
for epoch in range(num_epochs):
# 1) train
train_loss, train_acc = train_one_epoch(
model=net,
loader=trainloader,
criterion=criterion,
optimizer=optimizer,
device=device
)
# 2) validation
# test set이 아니라 validation set으로만 중간 성능 확인
val_loss, val_acc = evaluate(
model=net,
loader=valloader,
criterion=criterion,
device=device
)
# 3) scheduler step
scheduler.step()
current_lr = optimizer.param_groups[0]['lr']
# 4) 기록 저장
train_losses.append(train_loss)
train_accs.append(train_acc)
val_losses.append(val_loss)
val_accs.append(val_acc)
# 5) best validation checkpoint 저장
# test accuracy가 아니라 val accuracy 기준으로 저장하는 것이 핵심
if val_acc > best_val_acc:
best_val_acc = val_acc
best_epoch = epoch + 1
best_model_wts = copy.deepcopy(net.state_dict())
# 6) 로그 출력
print(
f"Epoch [{epoch+1}/{num_epochs}] | "
f"LR: {current_lr:.5f} | "
f"Train Loss: {train_loss:.4f} | "
f"Train Acc: {train_acc:.2f}% | "
f"Val Loss: {val_loss:.4f} | "
f"Val Acc: {val_acc:.2f}% | "
f"Best Val Acc: {best_val_acc:.2f}%"
)
print("----- Finished Training -----")
print(f"Best Validation Accuracy: {best_val_acc:.2f}% (Epoch {best_epoch})")
# =========================================================
# 10. 최종 테스트
# =========================================================
# 학습이 끝난 뒤, validation 성능이 가장 좋았던 checkpoint를 불러와서
# test set으로 단 한 번 최종 평가
net.load_state_dict(best_model_wts)
test_loss, test_acc = evaluate(
model=net,
loader=testloader,
criterion=criterion,
device=device
)
print("----- Final Test Result -----")
print(f"Test Loss: {test_loss:.4f}")
print(f"Final Test Accuracy: {test_acc:.2f}%")
# =========================================================
# 11. learning curve 시각화
# =========================================================
epochs = list(range(1, num_epochs + 1))
plt.figure(figsize=(12, 5))
# (1) Loss curve
plt.subplot(1, 2, 1)
plt.plot(epochs, train_losses, label='Train Loss')
plt.plot(epochs, val_losses, label='Validation Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Learning Curve - Loss')
plt.legend()
plt.grid(True)
# (2) Accuracy curve
plt.subplot(1, 2, 2)
plt.plot(epochs, train_accs, label='Train Accuracy')
plt.plot(epochs, val_accs, label='Validation Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy (%)')
plt.title('Learning Curve - Accuracy')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
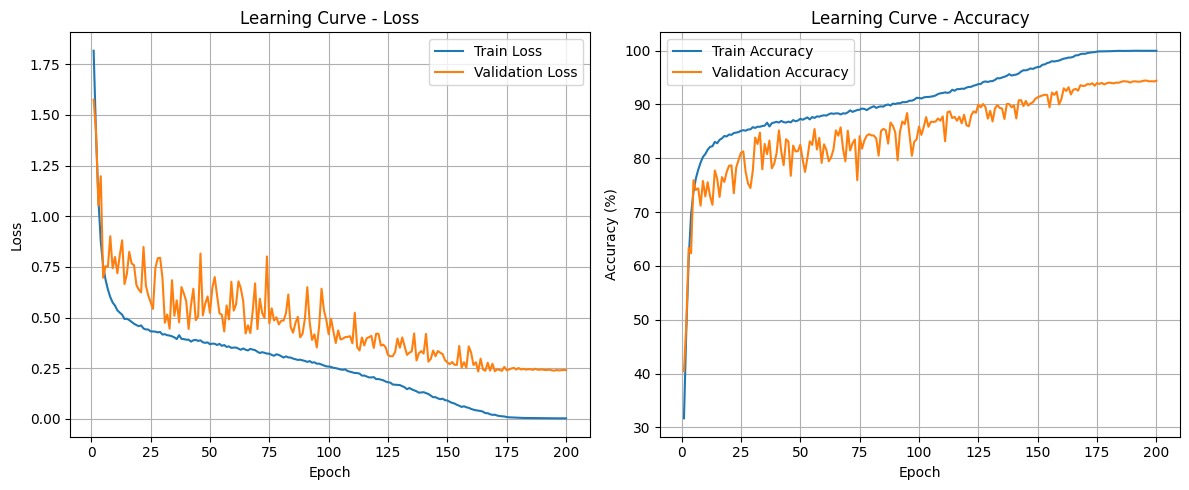
결과
Best Accuracy: 94.02
Device: cuda
100%|██████████| 170M/170M [00:03<00:00, 47.3MB/s]
----- Start Training -----
Epoch [1/200] | LR: 0.09999 | Train Loss: 1.8169 | Train Acc: 31.69% | Val Loss: 1.5755 | Val Acc: 40.44% | Best Val Acc: 40.44%
Epoch [2/200] | LR: 0.09998 | Train Loss: 1.4028 | Train Acc: 48.24% | Val Loss: 1.4191 | Val Acc: 49.32% | Best Val Acc: 49.32%
Epoch [3/200] | LR: 0.09994 | Train Loss: 1.0848 | Train Acc: 61.30% | Val Loss: 1.0529 | Val Acc: 63.38% | Best Val Acc: 63.38%
Epoch [4/200] | LR: 0.09990 | Train Loss: 0.8743 | Train Acc: 69.55% | Val Loss: 1.1976 | Val Acc: 62.36% | Best Val Acc: 63.38%
Epoch [5/200] | LR: 0.09985 | Train Loss: 0.7575 | Train Acc: 73.73% | Val Loss: 0.6967 | Val Acc: 75.92% | Best Val Acc: 75.92%
Epoch [6/200] | LR: 0.09978 | Train Loss: 0.6877 | Train Acc: 76.22% | Val Loss: 0.7533 | Val Acc: 74.12% | Best Val Acc: 75.92%
Epoch [7/200] | LR: 0.09970 | Train Loss: 0.6386 | Train Acc: 77.86% | Val Loss: 0.7510 | Val Acc: 74.40% | Best Val Acc: 75.92%
Epoch [8/200] | LR: 0.09961 | Train Loss: 0.6012 | Train Acc: 79.20% | Val Loss: 0.9016 | Val Acc: 71.20% | Best Val Acc: 75.92%
Epoch [9/200] | LR: 0.09950 | Train Loss: 0.5745 | Train Acc: 80.24% | Val Loss: 0.7436 | Val Acc: 75.78% | Best Val Acc: 75.92%
Epoch [10/200] | LR: 0.09938 | Train Loss: 0.5589 | Train Acc: 80.80% | Val Loss: 0.7991 | Val Acc: 72.92% | Best Val Acc: 75.92%
Epoch [11/200] | LR: 0.09926 | Train Loss: 0.5357 | Train Acc: 81.60% | Val Loss: 0.7188 | Val Acc: 75.54% | Best Val Acc: 75.92%
Epoch [12/200] | LR: 0.09911 | Train Loss: 0.5246 | Train Acc: 82.12% | Val Loss: 0.8074 | Val Acc: 72.96% | Best Val Acc: 75.92%
Epoch [13/200] | LR: 0.09896 | Train Loss: 0.5146 | Train Acc: 82.24% | Val Loss: 0.8813 | Val Acc: 71.36% | Best Val Acc: 75.92%
Epoch [14/200] | LR: 0.09880 | Train Loss: 0.4931 | Train Acc: 83.05% | Val Loss: 0.6657 | Val Acc: 77.74% | Best Val Acc: 77.74%
Epoch [15/200] | LR: 0.09862 | Train Loss: 0.4943 | Train Acc: 82.79% | Val Loss: 0.7153 | Val Acc: 76.20% | Best Val Acc: 77.74%
Epoch [16/200] | LR: 0.09843 | Train Loss: 0.4875 | Train Acc: 83.42% | Val Loss: 0.8242 | Val Acc: 72.82% | Best Val Acc: 77.74%
Epoch [17/200] | LR: 0.09823 | Train Loss: 0.4786 | Train Acc: 83.70% | Val Loss: 0.7668 | Val Acc: 76.50% | Best Val Acc: 77.74%
Epoch [18/200] | LR: 0.09801 | Train Loss: 0.4698 | Train Acc: 84.14% | Val Loss: 0.7592 | Val Acc: 75.62% | Best Val Acc: 77.74%
Epoch [19/200] | LR: 0.09779 | Train Loss: 0.4633 | Train Acc: 84.05% | Val Loss: 0.6618 | Val Acc: 77.46% | Best Val Acc: 77.74%
Epoch [20/200] | LR: 0.09755 | Train Loss: 0.4576 | Train Acc: 84.42% | Val Loss: 0.6378 | Val Acc: 78.62% | Best Val Acc: 78.62%
Epoch [21/200] | LR: 0.09730 | Train Loss: 0.4614 | Train Acc: 84.35% | Val Loss: 0.6244 | Val Acc: 78.68% | Best Val Acc: 78.68%
Epoch [22/200] | LR: 0.09704 | Train Loss: 0.4463 | Train Acc: 84.68% | Val Loss: 0.8485 | Val Acc: 73.52% | Best Val Acc: 78.68%
Epoch [23/200] | LR: 0.09677 | Train Loss: 0.4415 | Train Acc: 84.78% | Val Loss: 0.6589 | Val Acc: 78.26% | Best Val Acc: 78.68%
Epoch [24/200] | LR: 0.09649 | Train Loss: 0.4411 | Train Acc: 84.86% | Val Loss: 0.6093 | Val Acc: 79.70% | Best Val Acc: 79.70%
Epoch [25/200] | LR: 0.09619 | Train Loss: 0.4321 | Train Acc: 85.11% | Val Loss: 0.5754 | Val Acc: 81.00% | Best Val Acc: 81.00%
Epoch [26/200] | LR: 0.09589 | Train Loss: 0.4317 | Train Acc: 85.22% | Val Loss: 0.5428 | Val Acc: 81.28% | Best Val Acc: 81.28%
Epoch [27/200] | LR: 0.09557 | Train Loss: 0.4305 | Train Acc: 85.12% | Val Loss: 0.7446 | Val Acc: 77.40% | Best Val Acc: 81.28%
Epoch [28/200] | LR: 0.09524 | Train Loss: 0.4271 | Train Acc: 85.35% | Val Loss: 0.7931 | Val Acc: 75.30% | Best Val Acc: 81.28%
Epoch [29/200] | LR: 0.09490 | Train Loss: 0.4290 | Train Acc: 85.38% | Val Loss: 0.7950 | Val Acc: 74.48% | Best Val Acc: 81.28%
Epoch [30/200] | LR: 0.09455 | Train Loss: 0.4164 | Train Acc: 85.78% | Val Loss: 0.6933 | Val Acc: 77.70% | Best Val Acc: 81.28%
Epoch [31/200] | LR: 0.09419 | Train Loss: 0.4180 | Train Acc: 85.64% | Val Loss: 0.4746 | Val Acc: 83.86% | Best Val Acc: 83.86%
Epoch [32/200] | LR: 0.09382 | Train Loss: 0.4131 | Train Acc: 85.87% | Val Loss: 0.5151 | Val Acc: 82.66% | Best Val Acc: 83.86%
Epoch [33/200] | LR: 0.09343 | Train Loss: 0.4112 | Train Acc: 85.85% | Val Loss: 0.4454 | Val Acc: 84.76% | Best Val Acc: 84.76%
Epoch [34/200] | LR: 0.09304 | Train Loss: 0.4076 | Train Acc: 86.00% | Val Loss: 0.6845 | Val Acc: 77.96% | Best Val Acc: 84.76%
Epoch [35/200] | LR: 0.09263 | Train Loss: 0.4024 | Train Acc: 86.06% | Val Loss: 0.5090 | Val Acc: 82.66% | Best Val Acc: 84.76%
Epoch [36/200] | LR: 0.09222 | Train Loss: 0.3940 | Train Acc: 86.61% | Val Loss: 0.5847 | Val Acc: 80.76% | Best Val Acc: 84.76%
Epoch [37/200] | LR: 0.09179 | Train Loss: 0.4131 | Train Acc: 85.91% | Val Loss: 0.4768 | Val Acc: 83.28% | Best Val Acc: 84.76%
Epoch [38/200] | LR: 0.09135 | Train Loss: 0.3950 | Train Acc: 86.52% | Val Loss: 0.6506 | Val Acc: 78.14% | Best Val Acc: 84.76%
Epoch [39/200] | LR: 0.09091 | Train Loss: 0.3940 | Train Acc: 86.64% | Val Loss: 0.6182 | Val Acc: 78.96% | Best Val Acc: 84.76%
Epoch [40/200] | LR: 0.09045 | Train Loss: 0.3908 | Train Acc: 86.77% | Val Loss: 0.5810 | Val Acc: 80.92% | Best Val Acc: 84.76%
Epoch [41/200] | LR: 0.08998 | Train Loss: 0.3913 | Train Acc: 86.63% | Val Loss: 0.4438 | Val Acc: 85.18% | Best Val Acc: 85.18%
Epoch [42/200] | LR: 0.08951 | Train Loss: 0.3816 | Train Acc: 86.94% | Val Loss: 0.5621 | Val Acc: 81.20% | Best Val Acc: 85.18%
Epoch [43/200] | LR: 0.08902 | Train Loss: 0.3880 | Train Acc: 86.71% | Val Loss: 0.6422 | Val Acc: 78.72% | Best Val Acc: 85.18%
Epoch [44/200] | LR: 0.08853 | Train Loss: 0.3901 | Train Acc: 86.64% | Val Loss: 0.4872 | Val Acc: 83.54% | Best Val Acc: 85.18%
Epoch [45/200] | LR: 0.08802 | Train Loss: 0.3849 | Train Acc: 86.81% | Val Loss: 0.5052 | Val Acc: 83.12% | Best Val Acc: 85.18%
Epoch [46/200] | LR: 0.08751 | Train Loss: 0.3877 | Train Acc: 86.68% | Val Loss: 0.8159 | Val Acc: 76.74% | Best Val Acc: 85.18%
Epoch [47/200] | LR: 0.08698 | Train Loss: 0.3781 | Train Acc: 87.09% | Val Loss: 0.5109 | Val Acc: 82.36% | Best Val Acc: 85.18%
Epoch [48/200] | LR: 0.08645 | Train Loss: 0.3755 | Train Acc: 86.88% | Val Loss: 0.5688 | Val Acc: 81.28% | Best Val Acc: 85.18%
Epoch [49/200] | LR: 0.08591 | Train Loss: 0.3776 | Train Acc: 87.01% | Val Loss: 0.6043 | Val Acc: 81.32% | Best Val Acc: 85.18%
Epoch [50/200] | LR: 0.08536 | Train Loss: 0.3686 | Train Acc: 87.33% | Val Loss: 0.5236 | Val Acc: 82.50% | Best Val Acc: 85.18%
Epoch [51/200] | LR: 0.08480 | Train Loss: 0.3715 | Train Acc: 87.15% | Val Loss: 0.6470 | Val Acc: 79.78% | Best Val Acc: 85.18%
Epoch [52/200] | LR: 0.08423 | Train Loss: 0.3709 | Train Acc: 87.37% | Val Loss: 0.7000 | Val Acc: 77.46% | Best Val Acc: 85.18%
Epoch [53/200] | LR: 0.08365 | Train Loss: 0.3648 | Train Acc: 87.59% | Val Loss: 0.6083 | Val Acc: 80.08% | Best Val Acc: 85.18%
Epoch [54/200] | LR: 0.08307 | Train Loss: 0.3704 | Train Acc: 87.22% | Val Loss: 0.5216 | Val Acc: 83.14% | Best Val Acc: 85.18%
Epoch [55/200] | LR: 0.08247 | Train Loss: 0.3606 | Train Acc: 87.67% | Val Loss: 0.5142 | Val Acc: 82.48% | Best Val Acc: 85.18%
Epoch [56/200] | LR: 0.08187 | Train Loss: 0.3646 | Train Acc: 87.49% | Val Loss: 0.4317 | Val Acc: 85.44% | Best Val Acc: 85.44%
Epoch [57/200] | LR: 0.08126 | Train Loss: 0.3554 | Train Acc: 87.78% | Val Loss: 0.5597 | Val Acc: 81.64% | Best Val Acc: 85.44%
Epoch [58/200] | LR: 0.08065 | Train Loss: 0.3579 | Train Acc: 87.73% | Val Loss: 0.4908 | Val Acc: 83.78% | Best Val Acc: 85.44%
Epoch [59/200] | LR: 0.08002 | Train Loss: 0.3505 | Train Acc: 87.90% | Val Loss: 0.6770 | Val Acc: 79.14% | Best Val Acc: 85.44%
Epoch [60/200] | LR: 0.07939 | Train Loss: 0.3521 | Train Acc: 87.99% | Val Loss: 0.5342 | Val Acc: 82.60% | Best Val Acc: 85.44%
Epoch [61/200] | LR: 0.07875 | Train Loss: 0.3521 | Train Acc: 87.93% | Val Loss: 0.5656 | Val Acc: 81.54% | Best Val Acc: 85.44%
Epoch [62/200] | LR: 0.07810 | Train Loss: 0.3465 | Train Acc: 88.18% | Val Loss: 0.6790 | Val Acc: 79.44% | Best Val Acc: 85.44%
Epoch [63/200] | LR: 0.07745 | Train Loss: 0.3412 | Train Acc: 88.34% | Val Loss: 0.6440 | Val Acc: 80.18% | Best Val Acc: 85.44%
Epoch [64/200] | LR: 0.07679 | Train Loss: 0.3476 | Train Acc: 88.26% | Val Loss: 0.5812 | Val Acc: 81.70% | Best Val Acc: 85.44%
Epoch [65/200] | LR: 0.07612 | Train Loss: 0.3415 | Train Acc: 88.34% | Val Loss: 0.4214 | Val Acc: 85.18% | Best Val Acc: 85.44%
Epoch [66/200] | LR: 0.07545 | Train Loss: 0.3380 | Train Acc: 88.34% | Val Loss: 0.4620 | Val Acc: 84.20% | Best Val Acc: 85.44%
Epoch [67/200] | LR: 0.07477 | Train Loss: 0.3458 | Train Acc: 88.15% | Val Loss: 0.4238 | Val Acc: 85.74% | Best Val Acc: 85.74%
Epoch [68/200] | LR: 0.07409 | Train Loss: 0.3420 | Train Acc: 88.35% | Val Loss: 0.5318 | Val Acc: 81.76% | Best Val Acc: 85.74%
Epoch [69/200] | LR: 0.07340 | Train Loss: 0.3394 | Train Acc: 88.31% | Val Loss: 0.6687 | Val Acc: 79.44% | Best Val Acc: 85.74%
Epoch [70/200] | LR: 0.07270 | Train Loss: 0.3314 | Train Acc: 88.53% | Val Loss: 0.4430 | Val Acc: 85.12% | Best Val Acc: 85.74%
Epoch [71/200] | LR: 0.07200 | Train Loss: 0.3252 | Train Acc: 88.90% | Val Loss: 0.5930 | Val Acc: 81.44% | Best Val Acc: 85.74%
Epoch [72/200] | LR: 0.07129 | Train Loss: 0.3293 | Train Acc: 88.62% | Val Loss: 0.5221 | Val Acc: 82.78% | Best Val Acc: 85.74%
Epoch [73/200] | LR: 0.07058 | Train Loss: 0.3262 | Train Acc: 88.80% | Val Loss: 0.4974 | Val Acc: 83.50% | Best Val Acc: 85.74%
Epoch [74/200] | LR: 0.06986 | Train Loss: 0.3221 | Train Acc: 88.95% | Val Loss: 0.8017 | Val Acc: 75.94% | Best Val Acc: 85.74%
Epoch [75/200] | LR: 0.06913 | Train Loss: 0.3222 | Train Acc: 89.04% | Val Loss: 0.4713 | Val Acc: 84.10% | Best Val Acc: 85.74%
Epoch [76/200] | LR: 0.06841 | Train Loss: 0.3158 | Train Acc: 89.23% | Val Loss: 0.5455 | Val Acc: 81.78% | Best Val Acc: 85.74%
Epoch [77/200] | LR: 0.06767 | Train Loss: 0.3117 | Train Acc: 89.16% | Val Loss: 0.4859 | Val Acc: 83.32% | Best Val Acc: 85.74%
Epoch [78/200] | LR: 0.06694 | Train Loss: 0.3189 | Train Acc: 88.95% | Val Loss: 0.5012 | Val Acc: 84.20% | Best Val Acc: 85.74%
Epoch [79/200] | LR: 0.06620 | Train Loss: 0.3158 | Train Acc: 89.25% | Val Loss: 0.4663 | Val Acc: 84.48% | Best Val Acc: 85.74%
Epoch [80/200] | LR: 0.06545 | Train Loss: 0.3097 | Train Acc: 89.47% | Val Loss: 0.4846 | Val Acc: 84.26% | Best Val Acc: 85.74%
Epoch [81/200] | LR: 0.06470 | Train Loss: 0.3028 | Train Acc: 89.67% | Val Loss: 0.4851 | Val Acc: 84.22% | Best Val Acc: 85.74%
Epoch [82/200] | LR: 0.06395 | Train Loss: 0.3088 | Train Acc: 89.35% | Val Loss: 0.5214 | Val Acc: 83.66% | Best Val Acc: 85.74%
Epoch [83/200] | LR: 0.06319 | Train Loss: 0.3034 | Train Acc: 89.56% | Val Loss: 0.6139 | Val Acc: 80.50% | Best Val Acc: 85.74%
Epoch [84/200] | LR: 0.06243 | Train Loss: 0.3028 | Train Acc: 89.64% | Val Loss: 0.4532 | Val Acc: 85.06% | Best Val Acc: 85.74%
Epoch [85/200] | LR: 0.06167 | Train Loss: 0.2976 | Train Acc: 89.60% | Val Loss: 0.4255 | Val Acc: 85.46% | Best Val Acc: 85.74%
Epoch [86/200] | LR: 0.06091 | Train Loss: 0.2947 | Train Acc: 89.88% | Val Loss: 0.4732 | Val Acc: 85.24% | Best Val Acc: 85.74%
Epoch [87/200] | LR: 0.06014 | Train Loss: 0.2911 | Train Acc: 89.99% | Val Loss: 0.5040 | Val Acc: 82.72% | Best Val Acc: 85.74%
Epoch [88/200] | LR: 0.05937 | Train Loss: 0.2922 | Train Acc: 89.80% | Val Loss: 0.4031 | Val Acc: 86.64% | Best Val Acc: 86.64%
Epoch [89/200] | LR: 0.05860 | Train Loss: 0.2890 | Train Acc: 90.16% | Val Loss: 0.4203 | Val Acc: 86.04% | Best Val Acc: 86.64%
Epoch [90/200] | LR: 0.05782 | Train Loss: 0.2860 | Train Acc: 90.08% | Val Loss: 0.4957 | Val Acc: 84.82% | Best Val Acc: 86.64%
Epoch [91/200] | LR: 0.05705 | Train Loss: 0.2815 | Train Acc: 90.23% | Val Loss: 0.6500 | Val Acc: 79.64% | Best Val Acc: 86.64%
Epoch [92/200] | LR: 0.05627 | Train Loss: 0.2855 | Train Acc: 90.22% | Val Loss: 0.4767 | Val Acc: 84.98% | Best Val Acc: 86.64%
Epoch [93/200] | LR: 0.05549 | Train Loss: 0.2777 | Train Acc: 90.43% | Val Loss: 0.3899 | Val Acc: 86.84% | Best Val Acc: 86.84%
Epoch [94/200] | LR: 0.05471 | Train Loss: 0.2793 | Train Acc: 90.42% | Val Loss: 0.4173 | Val Acc: 86.36% | Best Val Acc: 86.84%
Epoch [95/200] | LR: 0.05392 | Train Loss: 0.2725 | Train Acc: 90.48% | Val Loss: 0.3525 | Val Acc: 88.40% | Best Val Acc: 88.40%
Epoch [96/200] | LR: 0.05314 | Train Loss: 0.2728 | Train Acc: 90.70% | Val Loss: 0.4595 | Val Acc: 84.42% | Best Val Acc: 88.40%
Epoch [97/200] | LR: 0.05236 | Train Loss: 0.2684 | Train Acc: 90.70% | Val Loss: 0.6424 | Val Acc: 80.46% | Best Val Acc: 88.40%
Epoch [98/200] | LR: 0.05157 | Train Loss: 0.2646 | Train Acc: 90.89% | Val Loss: 0.5362 | Val Acc: 83.08% | Best Val Acc: 88.40%
Epoch [99/200] | LR: 0.05079 | Train Loss: 0.2593 | Train Acc: 91.23% | Val Loss: 0.4892 | Val Acc: 83.52% | Best Val Acc: 88.40%
Epoch [100/200] | LR: 0.05000 | Train Loss: 0.2585 | Train Acc: 91.21% | Val Loss: 0.4178 | Val Acc: 85.88% | Best Val Acc: 88.40%
Epoch [101/200] | LR: 0.04921 | Train Loss: 0.2564 | Train Acc: 91.11% | Val Loss: 0.4949 | Val Acc: 84.34% | Best Val Acc: 88.40%
Epoch [102/200] | LR: 0.04843 | Train Loss: 0.2522 | Train Acc: 91.30% | Val Loss: 0.4310 | Val Acc: 85.82% | Best Val Acc: 88.40%
Epoch [103/200] | LR: 0.04764 | Train Loss: 0.2503 | Train Acc: 91.39% | Val Loss: 0.3745 | Val Acc: 87.64% | Best Val Acc: 88.40%
Epoch [104/200] | LR: 0.04686 | Train Loss: 0.2476 | Train Acc: 91.39% | Val Loss: 0.4367 | Val Acc: 85.86% | Best Val Acc: 88.40%
Epoch [105/200] | LR: 0.04608 | Train Loss: 0.2440 | Train Acc: 91.46% | Val Loss: 0.3919 | Val Acc: 86.78% | Best Val Acc: 88.40%
Epoch [106/200] | LR: 0.04529 | Train Loss: 0.2426 | Train Acc: 91.53% | Val Loss: 0.3965 | Val Acc: 86.76% | Best Val Acc: 88.40%
Epoch [107/200] | LR: 0.04451 | Train Loss: 0.2442 | Train Acc: 91.67% | Val Loss: 0.4037 | Val Acc: 86.82% | Best Val Acc: 88.40%
Epoch [108/200] | LR: 0.04373 | Train Loss: 0.2363 | Train Acc: 91.93% | Val Loss: 0.4048 | Val Acc: 87.40% | Best Val Acc: 88.40%
Epoch [109/200] | LR: 0.04295 | Train Loss: 0.2331 | Train Acc: 92.07% | Val Loss: 0.4081 | Val Acc: 86.98% | Best Val Acc: 88.40%
Epoch [110/200] | LR: 0.04218 | Train Loss: 0.2300 | Train Acc: 92.12% | Val Loss: 0.3730 | Val Acc: 87.78% | Best Val Acc: 88.40%
Epoch [111/200] | LR: 0.04140 | Train Loss: 0.2266 | Train Acc: 92.25% | Val Loss: 0.5237 | Val Acc: 83.16% | Best Val Acc: 88.40%
Epoch [112/200] | LR: 0.04063 | Train Loss: 0.2261 | Train Acc: 92.15% | Val Loss: 0.3542 | Val Acc: 88.54% | Best Val Acc: 88.54%
Epoch [113/200] | LR: 0.03986 | Train Loss: 0.2238 | Train Acc: 92.26% | Val Loss: 0.3377 | Val Acc: 88.72% | Best Val Acc: 88.72%
Epoch [114/200] | LR: 0.03909 | Train Loss: 0.2137 | Train Acc: 92.73% | Val Loss: 0.4021 | Val Acc: 87.46% | Best Val Acc: 88.72%
Epoch [115/200] | LR: 0.03833 | Train Loss: 0.2141 | Train Acc: 92.54% | Val Loss: 0.3626 | Val Acc: 87.70% | Best Val Acc: 88.72%
Epoch [116/200] | LR: 0.03757 | Train Loss: 0.2094 | Train Acc: 92.84% | Val Loss: 0.3976 | Val Acc: 86.98% | Best Val Acc: 88.72%
Epoch [117/200] | LR: 0.03681 | Train Loss: 0.2048 | Train Acc: 92.85% | Val Loss: 0.4035 | Val Acc: 87.72% | Best Val Acc: 88.72%
Epoch [118/200] | LR: 0.03605 | Train Loss: 0.2047 | Train Acc: 92.93% | Val Loss: 0.4097 | Val Acc: 86.50% | Best Val Acc: 88.72%
Epoch [119/200] | LR: 0.03530 | Train Loss: 0.2062 | Train Acc: 92.90% | Val Loss: 0.3502 | Val Acc: 88.08% | Best Val Acc: 88.72%
Epoch [120/200] | LR: 0.03455 | Train Loss: 0.1964 | Train Acc: 93.14% | Val Loss: 0.4208 | Val Acc: 86.14% | Best Val Acc: 88.72%
Epoch [121/200] | LR: 0.03380 | Train Loss: 0.1969 | Train Acc: 93.25% | Val Loss: 0.4199 | Val Acc: 85.94% | Best Val Acc: 88.72%
Epoch [122/200] | LR: 0.03306 | Train Loss: 0.1937 | Train Acc: 93.28% | Val Loss: 0.3619 | Val Acc: 87.96% | Best Val Acc: 88.72%
Epoch [123/200] | LR: 0.03233 | Train Loss: 0.1906 | Train Acc: 93.48% | Val Loss: 0.3665 | Val Acc: 88.72% | Best Val Acc: 88.72%
Epoch [124/200] | LR: 0.03159 | Train Loss: 0.1844 | Train Acc: 93.60% | Val Loss: 0.3532 | Val Acc: 88.46% | Best Val Acc: 88.72%
Epoch [125/200] | LR: 0.03087 | Train Loss: 0.1808 | Train Acc: 93.79% | Val Loss: 0.3150 | Val Acc: 89.98% | Best Val Acc: 89.98%
Epoch [126/200] | LR: 0.03014 | Train Loss: 0.1791 | Train Acc: 93.80% | Val Loss: 0.3092 | Val Acc: 89.46% | Best Val Acc: 89.98%
Epoch [127/200] | LR: 0.02942 | Train Loss: 0.1697 | Train Acc: 94.17% | Val Loss: 0.3096 | Val Acc: 90.08% | Best Val Acc: 90.08%
Epoch [128/200] | LR: 0.02871 | Train Loss: 0.1689 | Train Acc: 94.27% | Val Loss: 0.3312 | Val Acc: 89.54% | Best Val Acc: 90.08%
Epoch [129/200] | LR: 0.02800 | Train Loss: 0.1681 | Train Acc: 94.18% | Val Loss: 0.3967 | Val Acc: 87.36% | Best Val Acc: 90.08%
Epoch [130/200] | LR: 0.02730 | Train Loss: 0.1669 | Train Acc: 94.31% | Val Loss: 0.3515 | Val Acc: 88.80% | Best Val Acc: 90.08%
Epoch [131/200] | LR: 0.02660 | Train Loss: 0.1615 | Train Acc: 94.34% | Val Loss: 0.4022 | Val Acc: 86.84% | Best Val Acc: 90.08%
Epoch [132/200] | LR: 0.02591 | Train Loss: 0.1561 | Train Acc: 94.56% | Val Loss: 0.3576 | Val Acc: 89.24% | Best Val Acc: 90.08%
Epoch [133/200] | LR: 0.02523 | Train Loss: 0.1465 | Train Acc: 94.88% | Val Loss: 0.3160 | Val Acc: 89.90% | Best Val Acc: 90.08%
Epoch [134/200] | LR: 0.02455 | Train Loss: 0.1526 | Train Acc: 94.85% | Val Loss: 0.3269 | Val Acc: 89.36% | Best Val Acc: 90.08%
Epoch [135/200] | LR: 0.02388 | Train Loss: 0.1460 | Train Acc: 94.99% | Val Loss: 0.3330 | Val Acc: 89.24% | Best Val Acc: 90.08%
Epoch [136/200] | LR: 0.02321 | Train Loss: 0.1409 | Train Acc: 95.15% | Val Loss: 0.4218 | Val Acc: 87.30% | Best Val Acc: 90.08%
Epoch [137/200] | LR: 0.02255 | Train Loss: 0.1364 | Train Acc: 95.32% | Val Loss: 0.2884 | Val Acc: 90.08% | Best Val Acc: 90.08%
Epoch [138/200] | LR: 0.02190 | Train Loss: 0.1295 | Train Acc: 95.63% | Val Loss: 0.3239 | Val Acc: 90.06% | Best Val Acc: 90.08%
Epoch [139/200] | LR: 0.02125 | Train Loss: 0.1309 | Train Acc: 95.37% | Val Loss: 0.3346 | Val Acc: 89.48% | Best Val Acc: 90.08%
Epoch [140/200] | LR: 0.02061 | Train Loss: 0.1318 | Train Acc: 95.48% | Val Loss: 0.3224 | Val Acc: 89.80% | Best Val Acc: 90.08%
Epoch [141/200] | LR: 0.01998 | Train Loss: 0.1276 | Train Acc: 95.55% | Val Loss: 0.4194 | Val Acc: 87.40% | Best Val Acc: 90.08%
Epoch [142/200] | LR: 0.01935 | Train Loss: 0.1230 | Train Acc: 95.75% | Val Loss: 0.2826 | Val Acc: 90.76% | Best Val Acc: 90.76%
Epoch [143/200] | LR: 0.01874 | Train Loss: 0.1152 | Train Acc: 96.10% | Val Loss: 0.2959 | Val Acc: 90.80% | Best Val Acc: 90.80%
Epoch [144/200] | LR: 0.01813 | Train Loss: 0.1072 | Train Acc: 96.36% | Val Loss: 0.3373 | Val Acc: 89.70% | Best Val Acc: 90.80%
Epoch [145/200] | LR: 0.01753 | Train Loss: 0.1074 | Train Acc: 96.34% | Val Loss: 0.3097 | Val Acc: 90.64% | Best Val Acc: 90.80%
Epoch [146/200] | LR: 0.01693 | Train Loss: 0.1013 | Train Acc: 96.47% | Val Loss: 0.3350 | Val Acc: 89.80% | Best Val Acc: 90.80%
Epoch [147/200] | LR: 0.01635 | Train Loss: 0.0974 | Train Acc: 96.69% | Val Loss: 0.3265 | Val Acc: 90.18% | Best Val Acc: 90.80%
Epoch [148/200] | LR: 0.01577 | Train Loss: 0.0998 | Train Acc: 96.60% | Val Loss: 0.3199 | Val Acc: 90.40% | Best Val Acc: 90.80%
Epoch [149/200] | LR: 0.01520 | Train Loss: 0.0926 | Train Acc: 96.82% | Val Loss: 0.2903 | Val Acc: 91.06% | Best Val Acc: 91.06%
Epoch [150/200] | LR: 0.01464 | Train Loss: 0.0910 | Train Acc: 96.95% | Val Loss: 0.2790 | Val Acc: 91.32% | Best Val Acc: 91.32%
Epoch [151/200] | LR: 0.01409 | Train Loss: 0.0844 | Train Acc: 97.01% | Val Loss: 0.2701 | Val Acc: 91.52% | Best Val Acc: 91.52%
Epoch [152/200] | LR: 0.01355 | Train Loss: 0.0792 | Train Acc: 97.37% | Val Loss: 0.2809 | Val Acc: 91.66% | Best Val Acc: 91.66%
Epoch [153/200] | LR: 0.01302 | Train Loss: 0.0762 | Train Acc: 97.44% | Val Loss: 0.2672 | Val Acc: 91.82% | Best Val Acc: 91.82%
Epoch [154/200] | LR: 0.01249 | Train Loss: 0.0697 | Train Acc: 97.69% | Val Loss: 0.2667 | Val Acc: 91.74% | Best Val Acc: 91.82%
Epoch [155/200] | LR: 0.01198 | Train Loss: 0.0650 | Train Acc: 97.81% | Val Loss: 0.3600 | Val Acc: 89.46% | Best Val Acc: 91.82%
Epoch [156/200] | LR: 0.01147 | Train Loss: 0.0592 | Train Acc: 98.04% | Val Loss: 0.2531 | Val Acc: 92.20% | Best Val Acc: 92.20%
Epoch [157/200] | LR: 0.01098 | Train Loss: 0.0622 | Train Acc: 97.98% | Val Loss: 0.2797 | Val Acc: 91.78% | Best Val Acc: 92.20%
Epoch [158/200] | LR: 0.01049 | Train Loss: 0.0574 | Train Acc: 98.08% | Val Loss: 0.2527 | Val Acc: 92.36% | Best Val Acc: 92.36%
Epoch [159/200] | LR: 0.01002 | Train Loss: 0.0548 | Train Acc: 98.15% | Val Loss: 0.3576 | Val Acc: 90.00% | Best Val Acc: 92.36%
Epoch [160/200] | LR: 0.00955 | Train Loss: 0.0494 | Train Acc: 98.34% | Val Loss: 0.3273 | Val Acc: 91.02% | Best Val Acc: 92.36%
Epoch [161/200] | LR: 0.00909 | Train Loss: 0.0455 | Train Acc: 98.51% | Val Loss: 0.2661 | Val Acc: 93.00% | Best Val Acc: 93.00%
Epoch [162/200] | LR: 0.00865 | Train Loss: 0.0427 | Train Acc: 98.58% | Val Loss: 0.2792 | Val Acc: 92.50% | Best Val Acc: 93.00%
Epoch [163/200] | LR: 0.00821 | Train Loss: 0.0410 | Train Acc: 98.71% | Val Loss: 0.2341 | Val Acc: 93.20% | Best Val Acc: 93.20%
Epoch [164/200] | LR: 0.00778 | Train Loss: 0.0391 | Train Acc: 98.72% | Val Loss: 0.2974 | Val Acc: 91.86% | Best Val Acc: 93.20%
Epoch [165/200] | LR: 0.00737 | Train Loss: 0.0357 | Train Acc: 98.85% | Val Loss: 0.2446 | Val Acc: 92.74% | Best Val Acc: 93.20%
Epoch [166/200] | LR: 0.00696 | Train Loss: 0.0285 | Train Acc: 99.13% | Val Loss: 0.2376 | Val Acc: 92.88% | Best Val Acc: 93.20%
Epoch [167/200] | LR: 0.00657 | Train Loss: 0.0283 | Train Acc: 99.14% | Val Loss: 0.2776 | Val Acc: 92.56% | Best Val Acc: 93.20%
Epoch [168/200] | LR: 0.00618 | Train Loss: 0.0230 | Train Acc: 99.35% | Val Loss: 0.2383 | Val Acc: 93.58% | Best Val Acc: 93.58%
Epoch [169/200] | LR: 0.00581 | Train Loss: 0.0201 | Train Acc: 99.42% | Val Loss: 0.2723 | Val Acc: 93.44% | Best Val Acc: 93.58%
Epoch [170/200] | LR: 0.00545 | Train Loss: 0.0208 | Train Acc: 99.41% | Val Loss: 0.2357 | Val Acc: 93.48% | Best Val Acc: 93.58%
Epoch [171/200] | LR: 0.00510 | Train Loss: 0.0165 | Train Acc: 99.56% | Val Loss: 0.2446 | Val Acc: 93.80% | Best Val Acc: 93.80%
Epoch [172/200] | LR: 0.00476 | Train Loss: 0.0144 | Train Acc: 99.62% | Val Loss: 0.2420 | Val Acc: 93.70% | Best Val Acc: 93.80%
Epoch [173/200] | LR: 0.00443 | Train Loss: 0.0129 | Train Acc: 99.69% | Val Loss: 0.2373 | Val Acc: 93.94% | Best Val Acc: 93.94%
Epoch [174/200] | LR: 0.00411 | Train Loss: 0.0121 | Train Acc: 99.70% | Val Loss: 0.2566 | Val Acc: 93.48% | Best Val Acc: 93.94%
Epoch [175/200] | LR: 0.00381 | Train Loss: 0.0091 | Train Acc: 99.82% | Val Loss: 0.2399 | Val Acc: 93.98% | Best Val Acc: 93.98%
Epoch [176/200] | LR: 0.00351 | Train Loss: 0.0080 | Train Acc: 99.85% | Val Loss: 0.2439 | Val Acc: 93.80% | Best Val Acc: 93.98%
Epoch [177/200] | LR: 0.00323 | Train Loss: 0.0074 | Train Acc: 99.86% | Val Loss: 0.2490 | Val Acc: 94.00% | Best Val Acc: 94.00%
Epoch [178/200] | LR: 0.00296 | Train Loss: 0.0064 | Train Acc: 99.89% | Val Loss: 0.2518 | Val Acc: 93.72% | Best Val Acc: 94.00%
Epoch [179/200] | LR: 0.00270 | Train Loss: 0.0060 | Train Acc: 99.89% | Val Loss: 0.2438 | Val Acc: 93.92% | Best Val Acc: 94.00%
Epoch [180/200] | LR: 0.00245 | Train Loss: 0.0060 | Train Acc: 99.88% | Val Loss: 0.2512 | Val Acc: 94.06% | Best Val Acc: 94.06%
Epoch [181/200] | LR: 0.00221 | Train Loss: 0.0053 | Train Acc: 99.90% | Val Loss: 0.2439 | Val Acc: 94.00% | Best Val Acc: 94.06%
Epoch [182/200] | LR: 0.00199 | Train Loss: 0.0048 | Train Acc: 99.92% | Val Loss: 0.2475 | Val Acc: 93.92% | Best Val Acc: 94.06%
Epoch [183/200] | LR: 0.00177 | Train Loss: 0.0047 | Train Acc: 99.93% | Val Loss: 0.2434 | Val Acc: 94.06% | Best Val Acc: 94.06%
Epoch [184/200] | LR: 0.00157 | Train Loss: 0.0041 | Train Acc: 99.96% | Val Loss: 0.2452 | Val Acc: 94.02% | Best Val Acc: 94.06%
Epoch [185/200] | LR: 0.00138 | Train Loss: 0.0041 | Train Acc: 99.95% | Val Loss: 0.2454 | Val Acc: 94.18% | Best Val Acc: 94.18%
Epoch [186/200] | LR: 0.00120 | Train Loss: 0.0037 | Train Acc: 99.96% | Val Loss: 0.2419 | Val Acc: 94.32% | Best Val Acc: 94.32%
Epoch [187/200] | LR: 0.00104 | Train Loss: 0.0039 | Train Acc: 99.94% | Val Loss: 0.2476 | Val Acc: 94.28% | Best Val Acc: 94.32%
Epoch [188/200] | LR: 0.00089 | Train Loss: 0.0035 | Train Acc: 99.96% | Val Loss: 0.2428 | Val Acc: 94.24% | Best Val Acc: 94.32%
Epoch [189/200] | LR: 0.00074 | Train Loss: 0.0036 | Train Acc: 99.95% | Val Loss: 0.2432 | Val Acc: 94.06% | Best Val Acc: 94.32%
Epoch [190/200] | LR: 0.00062 | Train Loss: 0.0032 | Train Acc: 99.98% | Val Loss: 0.2438 | Val Acc: 94.26% | Best Val Acc: 94.32%
Epoch [191/200] | LR: 0.00050 | Train Loss: 0.0031 | Train Acc: 99.98% | Val Loss: 0.2418 | Val Acc: 94.30% | Best Val Acc: 94.32%
Epoch [192/200] | LR: 0.00039 | Train Loss: 0.0032 | Train Acc: 99.97% | Val Loss: 0.2416 | Val Acc: 94.24% | Best Val Acc: 94.32%
Epoch [193/200] | LR: 0.00030 | Train Loss: 0.0032 | Train Acc: 99.97% | Val Loss: 0.2434 | Val Acc: 94.22% | Best Val Acc: 94.32%
Epoch [194/200] | LR: 0.00022 | Train Loss: 0.0033 | Train Acc: 99.97% | Val Loss: 0.2397 | Val Acc: 94.34% | Best Val Acc: 94.34%
Epoch [195/200] | LR: 0.00015 | Train Loss: 0.0032 | Train Acc: 99.96% | Val Loss: 0.2381 | Val Acc: 94.44% | Best Val Acc: 94.44%
Epoch [196/200] | LR: 0.00010 | Train Loss: 0.0029 | Train Acc: 99.98% | Val Loss: 0.2413 | Val Acc: 94.42% | Best Val Acc: 94.44%
Epoch [197/200] | LR: 0.00006 | Train Loss: 0.0030 | Train Acc: 99.98% | Val Loss: 0.2393 | Val Acc: 94.28% | Best Val Acc: 94.44%
Epoch [198/200] | LR: 0.00002 | Train Loss: 0.0029 | Train Acc: 99.97% | Val Loss: 0.2402 | Val Acc: 94.32% | Best Val Acc: 94.44%
Epoch [199/200] | LR: 0.00001 | Train Loss: 0.0032 | Train Acc: 99.96% | Val Loss: 0.2416 | Val Acc: 94.26% | Best Val Acc: 94.44%
Epoch [200/200] | LR: 0.00000 | Train Loss: 0.0029 | Train Acc: 99.97% | Val Loss: 0.2411 | Val Acc: 94.42% | Best Val Acc: 94.44%
----- Finished Training -----
Best Validation Accuracy: 94.44% (Epoch 195)
----- Final Test Result -----
Test Loss: 0.2443
Final Test Accuracy: 94.02%
'AI > 논문 리뷰' 카테고리의 다른 글
| Block 연산량 비교: VGGNet, ResNet, MobileNetV2 (0) | 2026.04.04 |
|---|---|
| [논문 리뷰] MobileNetV2 Implementation (0) | 2026.03.29 |
| [논문 리뷰] VGGNet 내용 정리 (0) | 2026.03.29 |
| [논문 리뷰] MobileNetV2 내용 정리 (2) | 2026.03.16 |
| [논문 리뷰] ResNet 내용 정리 (1) | 2026.03.01 |
'AI/논문 리뷰' Related Articles
more
