
nevertheless
[논문 리뷰] VGGNet 내용 정리 본문
짧게 요약하자면
- 매우 작은 3x3 Covolution 필터를 반복적으로 사용하는 구조
- 깊게 쌓은 네트워크를 통해 feature를 추출 (16~19 layers)
- 구조가 단순하여 이해하기 쉬움 (계속 쌓는 구조)
- 하지만 파라미터 수가 많고 연산량이 큼
ABSTRACT
- 연구 목표
CNN의 depth(깊이)가 accuracy에 미치는 영향 분석
- 방법
작은 3×3 conv를 여러 개 쌓아 depth 증가
- 결과
깊은 네트워크가 더 높은 성능
INTRODUCTION
성능 향상에 중요한 요소:
- 작은 receptive field
- 작은 stride
- depth 증가 (핵심)
연구 방향: 모든 layer에 3×3 conv를 사용하면서 depth를 증가시키는 방식 실험
Architecture
Input image
- 224 X 224 RGB
- 전처리는 RGB 평균값 빼주는 것만 적용
Conv layer
- 3×3 conv 사용
- stride = 1, padding = 1
Pooling layer
- Conv layer 다음에 적용되고, 총 5개의 max pooling layer로 구성된다.
- 2 x 2 사이즈, stride는 2
Fully Connected layer
- 4096 -> 4096 -> 1000 (총 3개 FC)
- 마지막은 softmax layer 적용
Configurations
- Depth: 11 ~ 19 layer
- A ~ E 모델
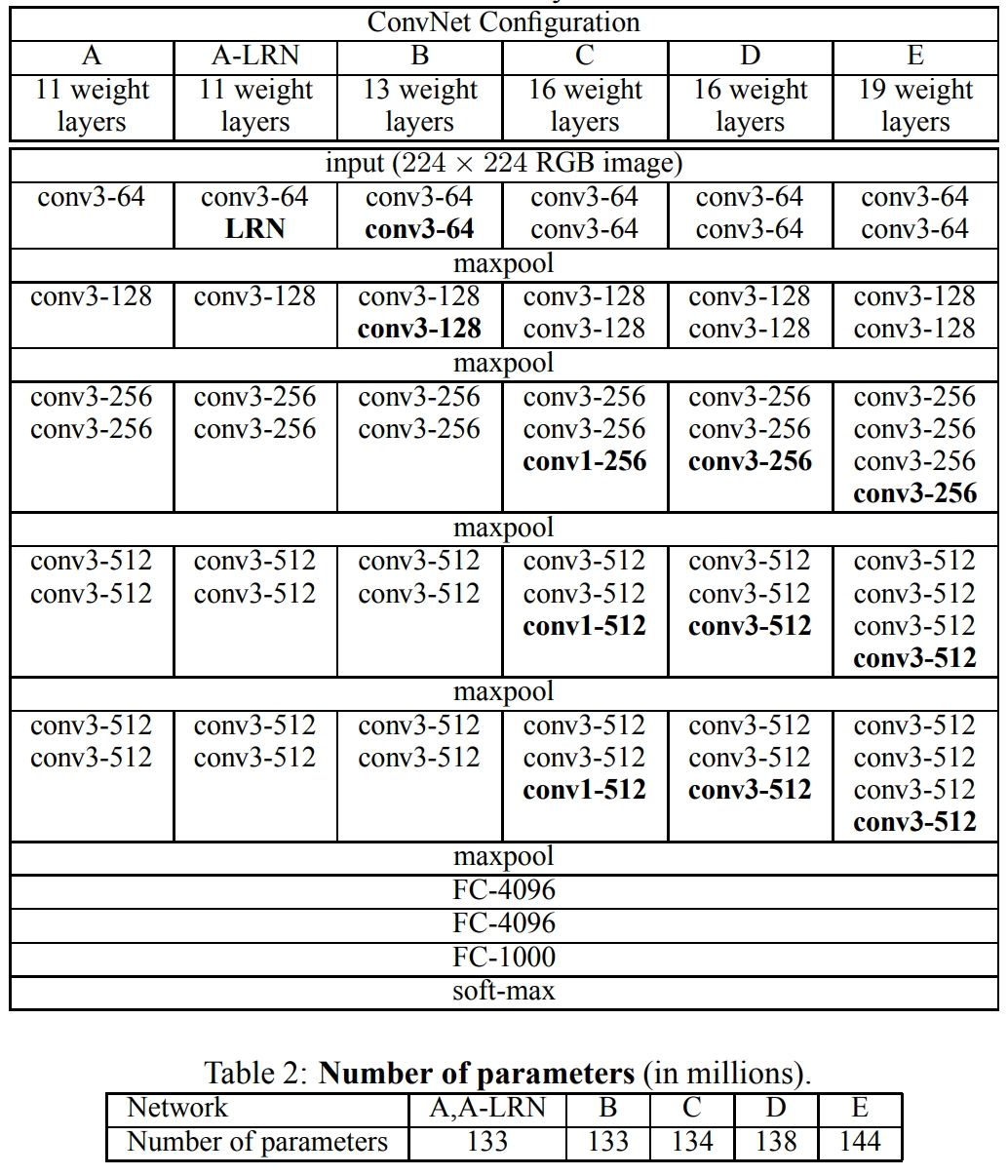
-> depth가 증가해도 큰 커널보다 작은 커널 여러 개가 오히려 효율적
Discussion
왜 3x3을 여러 개 쓰는가?
=> 핵심 이유 3가지
- Receptive field 동일
- 3×3 × 2 = 5×5 효과
- 3×3 × 3 = 7×7 효과
- Non-linearity 증가
- ReLU 함수 여러 번 통과
- 더 복잡한 함수 학습 가능
- Parameter 감소
- 예를 들어,
- 7x7 conv: 파라미터 많음
- 3x3 x 3: 더 적음
Expreriments Results
(1) depth 증가 → 성능 향상으로 이어짐
- 11 layer부터 19 layer까지 비교했을 때, 더 깊은 모델이 더 높은 정확도
(2) 작은 filter 구조가 더 우수
- 5x5나 7x7 같은 큰 필터 대신 3x3 필터를 여러 번 사용하는 구조가 더 좋은 성능을 보임
(3) LRN 효과 없음
- 기존 AlexNet에서 사용되던 LRN(Local Response Normalization)은 성능 향상에 거의 영향을 주지 않음
- 그래서 깊은 모델(B~E)에서는 안 씀
(4) scale jittering → 성능 개선
- 학습 시 이미지를 고정하지 않고 다양한 크기로 학습하는 scale jittering
- 다양한 scale의 feature를 학습할 수 있음
(5) multi-crop → 추가 성능
- 다양한 convolution 경계조건 때문에 dense 보완 가능
- 주변 이미지 정보가 자연스럽게 반영됨. 보는 문맥(context)가 다양함
Conclusion
- 우리가 한 것
- 최대 19개 weight layer
- 대규모 이미지 분류(ImageNet)
- 매우 깊은 CNN 실험
- 이를 통해 증명한 것
: depth(깊이)가 분류 정확도를 향상시킨다
- 복잡한 구조 없이 기존의 전통적인 ConvNet 구조를 유지해도 depth만 늘리면 최고 성능 가능
- 즉, 특별한 트릭 없이 깊게만 만들었음
- 일반화도 잘 됨
- 이 모델은 ImageNet 뿐만 아니라
- 다른 데이터셋, 다른 작업에도 잘 일반화됨
결론적으로, visual representation(시각적 표현)에서 depth(깊이)가 매우 중요하다는 것을 확인했다.
'AI > 논문 리뷰' 카테고리의 다른 글
| Block 연산량 비교: VGGNet, ResNet, MobileNetV2 (0) | 2026.04.04 |
|---|---|
| [논문 리뷰] MobileNetV2 Implementation (0) | 2026.03.29 |
| [논문 리뷰] ResNet Implementation (0) | 2026.03.29 |
| [논문 리뷰] MobileNetV2 내용 정리 (2) | 2026.03.16 |
| [논문 리뷰] ResNet 내용 정리 (1) | 2026.03.01 |
'AI/논문 리뷰' Related Articles
more
